Scaling Up Automated Testing Infrastructure While Scaling Down Costs
Capriza, as a mature SaaS startup company, servicing some large fortune 500 companies with high demands for a great SLA and an enterprise grade product, automating our QA testing processes has been a top priority from day one.
Providing companies with a platform for creating mobile micro apps over existing legacy enterprise applications, originally developed without any mobile capabilities in mind, has its challenges.
Our R&D teams translated these challenges into our current platform offering which consists of several components:
- A Designer tool where you record and style your mobile micro apps
- The WorkSimple mobile app that when installed takes advantage of native capabilities when running micro apps. These include push notifications, application updates, live slides showing KPI’s and more
- A Runtime component servicing a micro-app currently being executed
- The analytics Dashboard where you get all of your users and micro-apps usage metrics and control different aspects of your deployed apps
- Many other backend services such as our Relaybus **** which provides our users with advanced networking and security capabilities leveraging many of the cloud capabilities in order to provide the best experience possible while using our product from any location in the world

What does it take to ensure our platform quality?
Within Capriza, our QA Automation team took charge on creating our own internal testing framework named Watchdog, enabling them and others in the company to contribute and create many testing suites that when combined, provide an end-to-end full testing coverage for our platform.
Every single developer’s commit gets tested using those test suites, which in return provide fast feedback if anything breaks or creates a regression.
We also took advantage of that testing framework to monitor our customers deployed zapps by running them as “Heartbeat” tests. They are repeatedly executed at predefined intervals to check that the zapp is working as expected, also making sure that the backend application that the zapp was recorded against is online and working as expected.
We manage, execute and monitor these tests using a parallelized configuration of carefully tuned Jenkins jobs.
So far so good… what exactly is the problem?
As years go by and our platform expands and evolves, so does the number of developers and tests. This by itself is not a problem — by all means it’s the opposite of a problem. It is only natural that we develop and expand as the company grows.
The problem with the above is that our previously provisioned, static compute capacity (Jenkins Slaves) couldn't handle the increasing load fast enough and the Jenkins Job queue grew larger and larger, making developers wait longer times for their commits to be tested and be provided with the resulted feedback.
Running on AWS means that the easy solution for resolving the above is as easy as provisioning extra instances. At first we did just that. As we kept growing month by month, we kept on adding instances to a point we realized that our AWS bill grew out of budget.
We started looking for solutions for optimizing and lowering our compute needs and costs while keeping our testing services intact without harming the developers feedback time or our customers heartbeat monitoring.
We reached a conclusion that in order to dramatically lower our bills while keeping the compute capacity we need in order to provide the same performant testing service for our developers, we should turn to dedicated bare metal servers. We turned to a major bare metal servers provider which seemed a good candidate for our needs, providing large bare metal machines for a fraction (~40%) of the equivalent AWS compute capacity.
We knew that by offloading workload from AWS to bare metal machines we were willingly giving up on the ease of scalability and automations that AWS provides, for the manual setup and maintenance of the bare metal machines.
Yet, the value-for-money argument justified the move. That said, we still kept some of the workload on AWS for control reasons.
Soon after moving to bare metal machines we started experiencing an occasional instability in tests seen only in the bare metal machines. After deep investigations we concluded that those issues were due to the bare metal provider’s network not being as stable as what AWS provides. i.e requests that took an average of 300ms on AWS, took 3–4 times longer, causing our tests to take longer and fail on configured timeout thresholds.
Due to these instabilities we decided to consolidate our workload back into AWS which meant we were back at outgrowing our budget, but this time the tests stability and credibility outweighed the added expenses.
We kept on thinking of ways to optimize and improve our computing needs, such as changing some of the workload to be scheduled for our R&D working hours, automatically starting machines in the morning and scaling them down at evening. However, we knew that there must be a better way to handle our increasing load.
Using Spot Instances
We decided to give AWS spot instances a try, yet a simple implementation method was not available at that time and we didn't have the capacity to invest in creating one.

Image courtesy of Amazon Web Services
Around early June 2016, Spotinst released their elasticgroup Jenkins plugin. We were already familiar with Spotinst’s solution from their early on, yet we couldn't find a fit for them in our main product due to some technical limits with the spot reclamation policy — the 2 minutes termination notice.
Spotinst acts as a SaaS product which helps you optimize your cloud (AWS/ GCE/ Azure) bill. They are using machine learning to predict the spot prices. If a current spot price per hour is higher than an on-demand price then you’ll receive an on-demand instance. But if the price drops, you’ll be switched back to a spot instance. It’s really a simple yet effective mechanism.
We knew that this 2 minutes termination notice limit wouldn't be an issue for our Jenkins slaves use case and that it should be a good fit for our needs.
Leveraging Spot Instances with Spotinst and their Jenkins plugin
In order to implement their solution we had to take a few simple steps:
- We baked an AMI with all of our dependencies and automated the new AMI creation procedure, also updating the ElasticGroup configuration using the Spotinst REST API
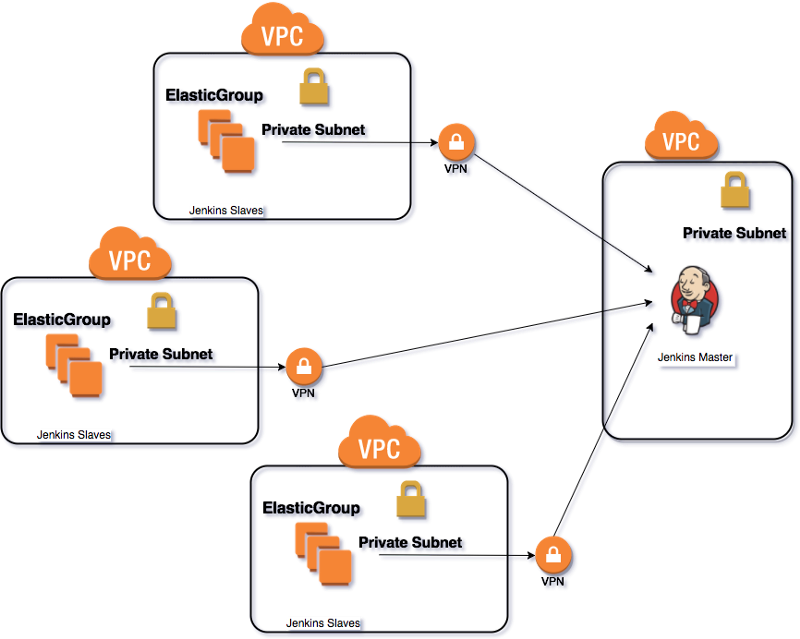
- We provisioned VPC’s on a few different AWS regions to achieve global presence for our testing for better coverage
- We connected all VPC’s to our Jenkins master using a VPN to create a secure connection between the Jenkins Slaves and the Jenkins Master.
- We created new ElasticGroups on the Spotinst console and configured them in the Spotinst Jenkins plugin with the relevant labels and executors weights per instance type.
There Are Some Caveats Though
- In order to leverage the Spotinst Jenkins plugin, we had to reverse the Jenkins node connection model, changing the direction of the connection from the default Master->Slave connection to a Slave->Master connection model
- Due to the fact that spot instances can be terminated within a two minute notice, we had to treat and manage our testing suites logs and metrics differently so we won’t lose them. To that end we implemented real time log shipping and parsed it to fit our needs which also resulted in a much better visibility of our testing results and feedbacks for our Automation team and our developers.
Implementation Results
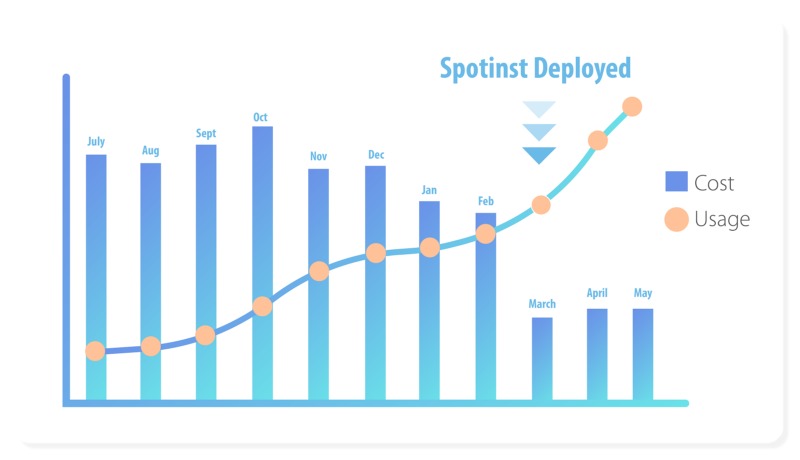
This spot implementation has been running our entire Automation Testing service for the last few months with great stability and credibility and for the time being, we haven’t received even one spot termination notice.
Enjoying a dynamically scaling Jenkins Slaves capacity resulted in a faster feedback for our developers and shorter job queue on our peak RnD hours.
As a result of using spot instances we see an average of 50% in costs savings in comparison to our previous on demand usage.
Moving forward, we are looking into more places where we could fit in the Spotinst solution.